The Import Data command invokes a process through which you can bring data records from an Excel file, delimited text file (*.csv), or fixed width text file into a new or existing ProVal database.
Note: The currently open ProVal database will receive the data. If this is not the database that you want to use, then execute the new database command or the open database command before importing the data.
If records already exist in the open database, ProVal will offer you the choice of either appending the imported records or using them to completely replace the prior database records. Note that if your objective is to merge imported data with data that is already in the database, as, for example, when you are updating data from one year to the next, you will need to first establish a new database into which you will import the current data and then use the Merge Data command to complete the data update process.
The basic steps of the import process (discussed in greater detail in the following paragraphs) involve identifying:
-
Format of the import file – whether the file is an Excel Worksheet, or, if a .csv or other text file (e.g., .txt), whether the Record format is Fixed Width or Delimited. (Typically, a .csv file would be delimited and a .txt file would be fixed width.) If you wish, you can load a saved record layout to populate the answers to the remaining steps. This might be useful, for instance, if you are re-importing a file.
-
Field locations in the import file, perhaps identified by selecting a saved Layout, and, for a .csv file, information about the Delimiter that separates the fields on records in the import file. For a fixed width text file, you specify the starting and ending columns and the width of each field contained on records in the file. For a delimited text file, you specify the delimiter character, the Start import at row number (rows before this one will be ignored) and whether the Start row contains field names. For an Excel file, you also specify the start import row number, whether the first row to import from contains the field names, and you select (from the list of Excel files in this client’s Databases are saved in directory) the Worksheet containing the data. For the delimiter, select either the Comma, Semicolon, Tab, Space or Other option, as appropriate; if Other is selected, enter the special character (for example, an ampersand) that separates fields.
-
Data in each field, as indicated by Field names and information. This data includes the field type (e.g., numeric, date, coded), the field codes for coded fields and the date formats for date fields. If ProVal finds a field that it cannot determine a name for, it will notify you when you click Next; in that case, click the field’s row (under the Field names and information parameter) and complete the parameters in the ensuing (Field Attributes) dialog box. You may ignore naming any fields you do not wish to import, by clicking the Skip this field box. For other unnamed fields, you may tell ProVal that its value either should be received by an already Existing field contained in the Data Dictionary or should become the value of a New field that you create now, by completing the remaining parameters of the Field Attributes dialog box. (For more information about the parameters for defining a new field, see Data Dictionary.)
-
Records to be imported, if not all records contained in the import file, as indicated by the Selection expression, which enables you to import only records that meet the criteria of your choice. If you leave the Selection expression box blank, then all records will be imported. Press the F1 key when your cursor is in this box to get a list of the operators you can use to create the expression.
When you select the external data file to import, a wizard will preview the records in the external file and walk you through the import process. Based on its preview of the records, the wizard may offer educated guesses about the data that you can either accept or modify. These educated guesses are particularly helpful in interpreting coded fields at the Data preview stage (the interpretation of data for coded fields is discussed more fully later on in this Help article). Note that the wizard will allow you to create Data Dictionary entries (that is, add new fields to this ProVal client), as well as modify existing entries. Thus the import process can be used at any stage of your ProVal data activity, even, for example, as the vehicle by means of which you establish a Data Dictionary for a new ProVal Client. Here is a snapshot of a sample ProVal dialog box for the “data preview” step of the wizard, illustrating the guessing for a .csv file with comma delimiters separating each field value:
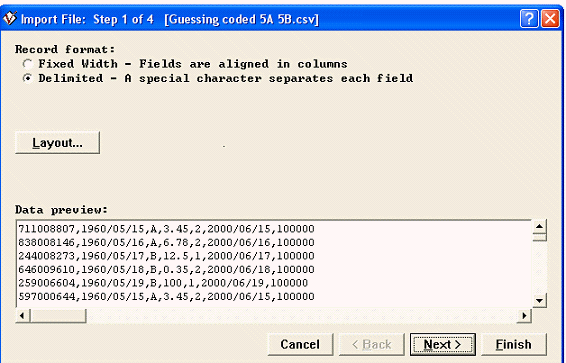
During the Import process, the wizard will create a Record Layout, retaining information about the import file. If a Record Layout with all or some of the data file information already exists at the outset, you can tell the wizard to start with that Record Layout and the wizard will then modify the information, if necessary, as you help it interpret the data. At the conclusion of the import process, you will have the option to save the new or modified Record Layout for potential re-use in subsequent imports.
If the first row of data contains field names, ProVal will match the name to the Data Dictionary. If the field name is marked as <skip>, ProVal will ignore the column during the import process. If the field name is not already in the Data Dictionary, ProVal will add it to the Data Dictionary with the field information entered in the import process.
Once you have finalized the Record Layout to be used in the import process, the wizard will enable you to use a Selection Expression to restrict the import to records that meet particular criteria with respect to the fields being imported. (This selection expression can be used, for example, to import only active records from a file that includes both active and inactive records.)
During the actual data import process, if there are conflicts between the file contents and the field types, codes, date formats, etc., ProVal will pause and ask you how to resolve the errors. A summary of the errors shows the name of the affected field, the number of erroneous records and the type of error. If you wish to see this information for each record, rather than in summary form, click the Details button. If you wish to have only a final error report, check Report errors only at end. Otherwise, the program will pause periodically with interim error reports. The Continue button resumes the import procedure. Click Cancel to quit without importing the data.
When the import is complete, ProVal displays a final count and description of the errors. Check the box entitled Save errors in the error log if you wish ProVal to record them for you.
To reduce the number of potential import errors for a coded field, the import wizard uses special handling for such fields when it is previewing the data to be imported and is building (or modifying) the Record Layout to be used. In the data previewing stage, the wizard will make assumptions about potential mappings, or will even guess at a mapping, although you will always have the opportunity to accept proposed mappings or modify those with which you disagree prior to the actual import.
The coded field mapping assumptions come into play in the wizard's interpretation of a file value that is the same as an existing label (character field type), or differs from the label only with respect to case, or that is the code value for an existing label; in each such situation, the wizard assumes that the file value should be mapped to the label involved.
When the wizard is building a new Record Layout, it can also offer guesses for file values that are similar to existing labels for the coded field. For example, if you have a coded field "Sex" with labels "M" and "F", the wizard will guess that a file value of "Male" should be mapped to the label "M." The mappings made under this "Allow similar matches" approach are displayed in a grid where you can either accept or modify them, as necessary. As with any of the wizard's mappings, you will again have the option to reject or modify the guesses when the wizard displays the Record Layout before the final import.
If you are using a pre-established Record Layout for the Import process and that layout includes mappings for a coded field, the wizard will start out with a more rigid interpretation of file values at the data preview stage. For example, it will not attempt to map file values that are merely similar to existing labels, because its assumption is that the Record Layout you are using already includes all desired mappings. To invite the wizard to guess, as it does when it is building a new Record Layout, you can choose the "Allow similar matches" option; the wizard will then display a grid with its reinterpretation of the file values.
If the database already has some records, you may either replace the records or append the new records to the end of the database. When you click Finish, ProVal will ask you whether to append or replace. As mentioned above, sometimes it may be necessary to merge the new data into the current database, rather than append to or replace the database. In that case, to merge the data, click Cancel and use the Merge/Update File command instead.
When importing a data file, you can provide an optional “schema file” that contains record layout and Data Dictionary information. If you have your own census management system, you might consider enhancing it to produce schema files. This will free users from having to key in information such as field names, types, etc. that was known in the census management system but isn’t contained in the data file.
By convention, import schema files end in the “.schema.csv” suffix. For example, if you are importing “<filename.ext>”, the corresponding schema file would be named “<filename.ext>.schema.csv” in the same folder. Note that since the schema file’s extension is .csv, it can be opened easily and edited in Excel. If “<filename.ext>.schema.csv” doesn't exist, ProVal will look for a "standard" schema file named “schema.csv” in the same folder. Otherwise, ProVal will assume that no schema file exists.
ProVal indicates the name of the data file you’re importing from and any corresponding schema file on the title bar of the Import Data wizard dialog box.
![]()
Schema example:
FIELD,SSN,Social Security Number,SSN,1,9,999-99-9999
FIELD,NAME,Name,CHARACTER,10,39,20
FIELD,SEX,Sex,CODED,40,40
CODE,SEX,,,,,,,M,1,MALE
CODE,SEX,,,,,,,F,2,FEMALE
FIELD,BIRTHDT,Birth Date,DATE,41,48,YYYYMMDD
FIELD,PAY,Pay,NUMERIC,49,58,"9,999,999.99",100
Schema format:
Note that the file contains two different types of records, FIELD and CODE, as indicated in position 1 (pos1).
pos1 = Record type, FIELD or CODE
pos2 = Field name
If pos1=FIELD, then pos3 - pos8 contain:
pos3 = Field description (optional)
pos4 = Field type, NUMERIC, CHARACTER, CODED, DATE, or SSN
pos5 = Field start position (optional; only relevant for fixed-width data)
pos6 = Field end position (optional; only relevant for fixed-width data)
pos7 = Field format (optional)
For NUMERIC fields, use a picture format such as "999,999.99"
For CHARACTER fields, display width (contained in the Field Attributes dialog box) in characters, e.g., 20
For DATE fields, use a picture format using YYYY, MM, DD, and /, e.g., YYYYMMDD
For SSN fields, use a picture format such as 999-99-9999
pos8 = Scaling factor for NUMERIC fields (optional)
If pos1=CODE, then pos9 - pos11 contain:
pos9 = Field value in import file
pos10 = Field code in ProVal database
pos11 = Field label in ProVal database (optional; default is same as pos9)
Notes:
-
Although the field format (pos7) is optional, its use is strongly encouraged for date fields.
-
Date formats with 2-digit years YY are tolerated but discouraged, because century breakpoints cannot be specified in the schema file.
-
Case-sensitive codes are discouraged because there is no way to specify that codes are case-sensitive in the schema file.
-
Items with embedded commas should be enclosed in quotes (e.g., the numeric format "9,999,999.99" in the example above).
-
Trailing commas can be omitted from each line.
-
Rows that don't start with FIELD or CODE will be ignored. This behavior allows comments to be added to the file.